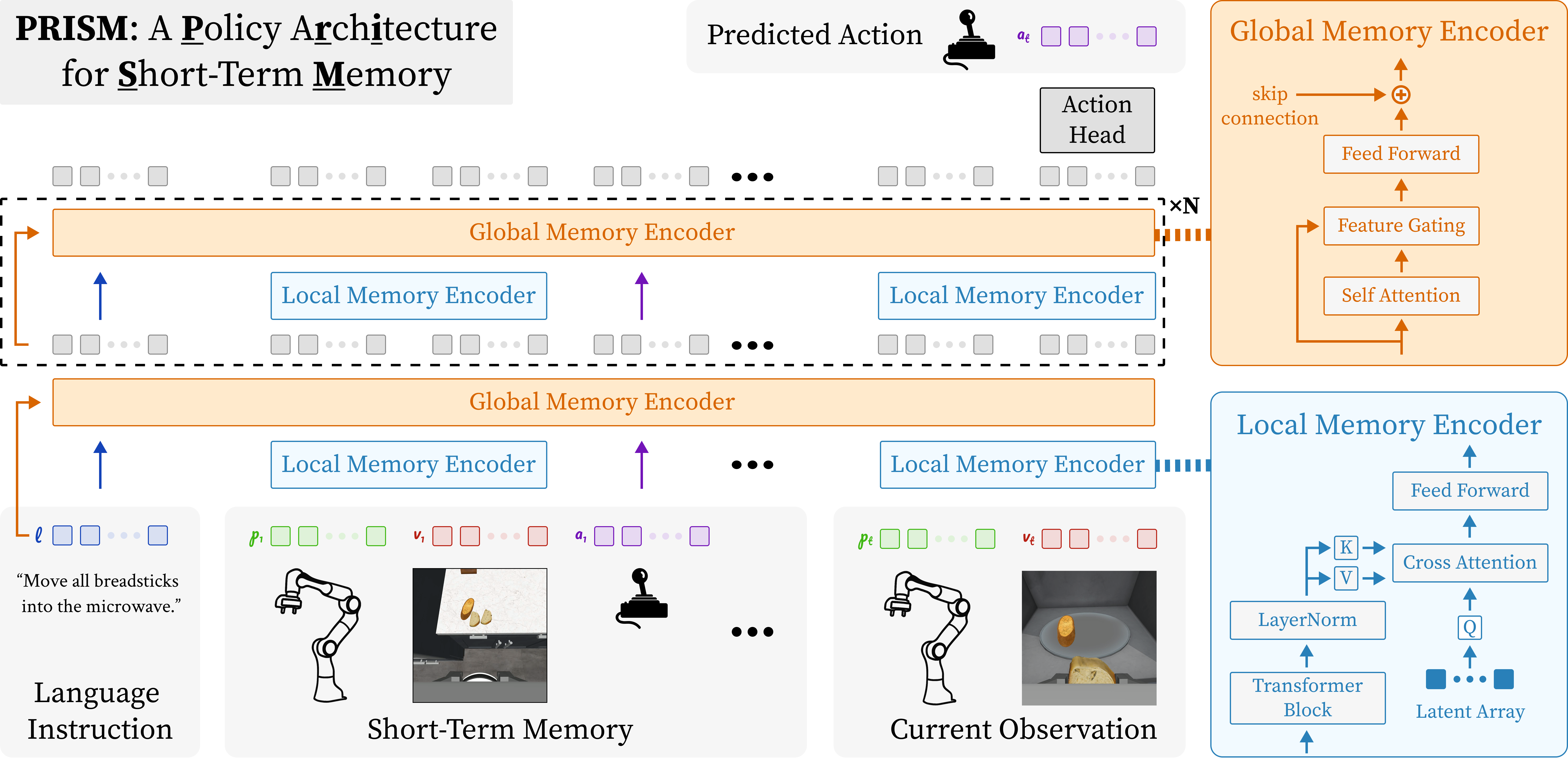
Method Overview
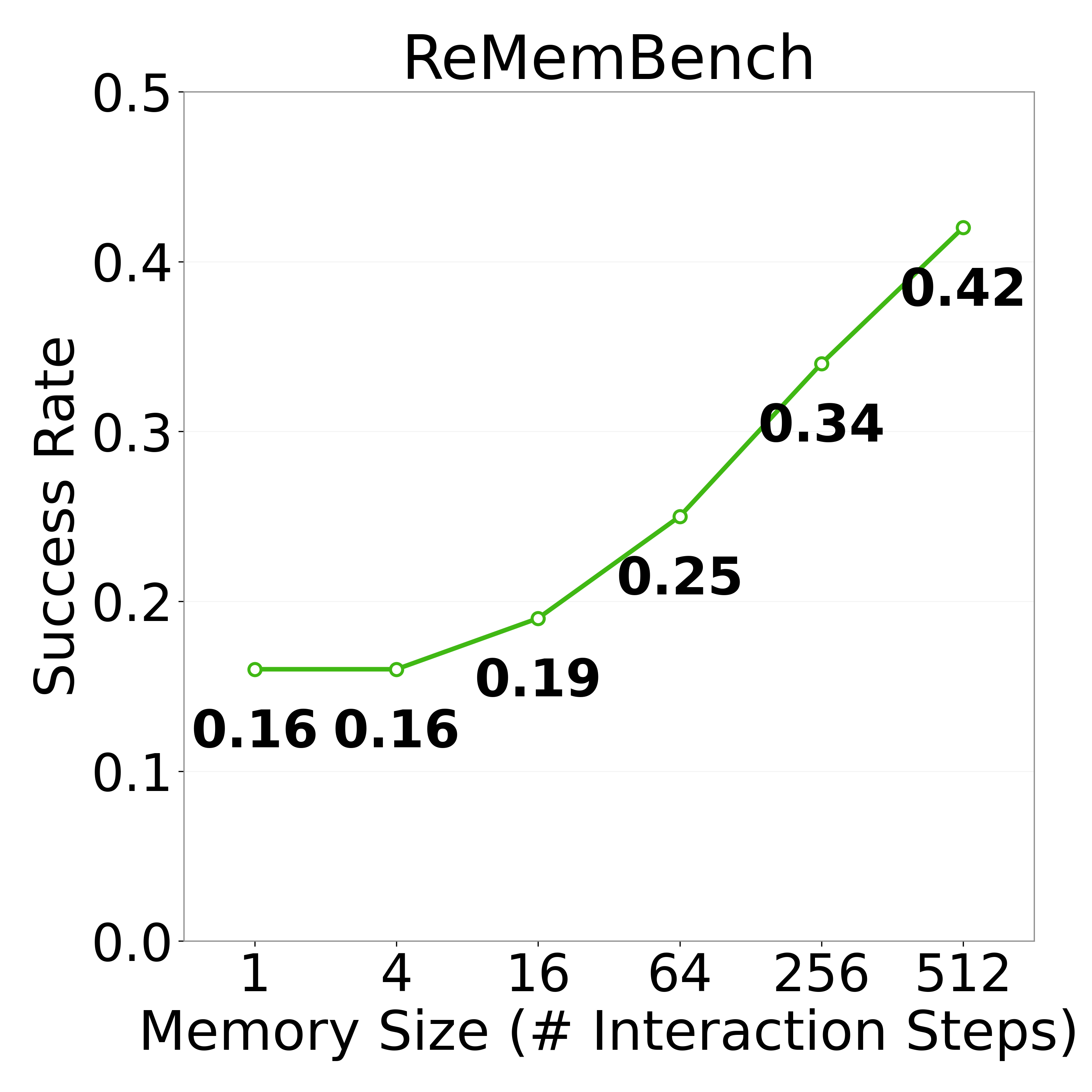
PRISM applies gated attention to filter information retrieved from history and hierarchical summarization to scale attention over long interaction histories, improving causal transformer policies trained with behavior cloning by improving robustness to noisy histories and reducing computation.